For the last several months I’ve been working on a manuscript to be included in an edited volume tentatively called Plant Gravitropism: Methods and Protocols. It is part of a series called Methods in Molecular Biology, published by Springer.
 My contribution focuses on ROTATO, the image analysis and feedback system we use routinely in my lab to measure root gravity responses. The objective of the series is to allow “a competent scientist who is unfamiliar with the method to carry out the technique successfully at the first attempt,” which seems pretty unlikely to me. I can’t think of a single experiment that I’ve every carried out successfully on the first try, but that’s another matter. I’ve been surprised by how hard it’s been to write this, so I thought I’d do some thinking out loud to try to gain a little insight into my struggle.
My contribution focuses on ROTATO, the image analysis and feedback system we use routinely in my lab to measure root gravity responses. The objective of the series is to allow “a competent scientist who is unfamiliar with the method to carry out the technique successfully at the first attempt,” which seems pretty unlikely to me. I can’t think of a single experiment that I’ve every carried out successfully on the first try, but that’s another matter. I’ve been surprised by how hard it’s been to write this, so I thought I’d do some thinking out loud to try to gain a little insight into my struggle.
I think some of my struggle has come from being too close to the method to see it with “beginner’s eyes.” I’ve been working with ROTATO since it was a pile of parts stripped from IBM PCs (we used the computer power supply for 5 V DC and the stepper motor from the floppy drive). I watched over my friend Jack’s shoulder as he wrote the software to make it work. I know the ins and outs of how it works and what makes for a good experiment. Through the years I’ve had a tough time teaching my students how to get good data with it, and I think that’s in part due to the hidden assumptions I make about it. Dragging those assumptions out into the light has been an ongoing process, and writing this paper has been helpful.
Another aspect of the struggle is with how to handle the software part of the method. I am not releasing the code (it’s not mine), and even if I could it wouldn’t do much good because of its dependence on an obsolete frame grabber card. So I’m trying to include enough detail about how it works to allow a scientist/programmer to reimplement the method. But I’m a biologist, not an engineer, so I’m struggling with how much to say and how to say it. I think this is the heart of the issue, that I’m trying to bridge the worlds of biology and engineering.
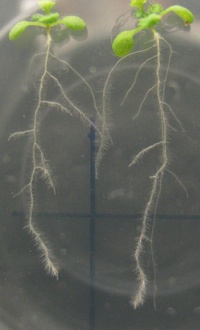
This is, in fact, what ROTATO is about, and what makes it so important. It takes pictures of a biological response and uses them to control the position of the organ doing the response. It is clever, naive in certain ways, clunky, finicky, crashy, and it works. It has allowed us to learn new things about how roots respond to gravity. So that’s what I’m trying to convey in this methods paper, how to make a ROTATO that works well enough to learn new things, of which there are plenty, I am sure.